
Here we are again, some 580+ commits and 1000+ modified files later, with 10 contributors involved (with particular thanks to @MDoerner and @BZngr, and honorable mentions to @IvenBach and @testingoutgith1) in over 60 pull requests since the last release: time to look back at what was done and call it version 2.5.1! If you’ve been keeping up with pre-release builds, none of this is going to be news to you, but with over 9.1K downloads of v2.5.0 a lot of you seem to prefer to upgrade less often but more significantly, so here’s a timely recap.
But first, let’s get the known problems out of the way.
Known Issues
Making a VBIDE add-in means we can’t know or assume what our host application is going to be, and different hosts sometimes wire things up differently – and this can spell trouble under certain circumstances. Making a VBIDE add-in in .NET has even further implications: while it’s how we can extend a 64-bit VBE, it’s also causing various type cast errors/exceptions when other add-ins are loaded.
Possible Crash
The Visual Basic Editor has a peculiar way of loading its add-ins: Rubberduck’s (and any other VBIDE add-in’s) entry point is invoked by the VBE before the VBE has completely finished constructing itself – accessing the object model too early can throw COM exceptions that take down Rubberduck as it initializes.
Normally Rubberduck initializes itself, then proceeds to parse the project (if it’s an empty project then the bulk of that is Rubberduck loading everything defined in VBA7.DLL and the type library for the host application’s object model) – normally if the VBE isn’t ready for this yet, we bail out and don’t access any objects and the “Refresh” button says “Pending” instead of “Ready”, and by the time you manually run that command the VBE has finished initializing and the only annoyance is that the initial parse isn’t automatic.
But in certain host applications (Microsoft Access being a known one, but I’ve seen it happen in Excel as well, although not with a recent build), sometimes the VBE actually isn’t ready to take member calls against its own object model, and the result is a COM exception that is either caught and then Rubberduck says it can’t initialize, or thrown several layers deeper, uncaught, and then everything goes up in flames.
Loading Rubberduck manually from the VBE’s Add-Ins Manager is sure annoying, but is really the only 100% sure-shot way to load any VBIDE add-in with a properly initialized VBE, regardless of the host application. Note that the installer registers Rubberduck as a VBE add-in with the LoadBehavior flag set to load at startup. If Rubberduck blows up at startup or fails to initialize, consider editing this configuration to make it load manually (exception details should normally be logged for the first start-up).
Heavy on Memory (RAM)
Rubberduck has always used a lot of memory to keep all the code metadata handy and cache a lot of things to improve processing performance. Working on a large legacy project that generates lots of inspection results can grind the main thread of the host process to a halt as the toolwindow renders the many objects (whether the toolwindow is displayed or not).
Unless you are discovering Rubberduck with a new, empty VBA project, consider first reviewing the settings – can’t hurt to review them either way:
- Disable “run inspections automatically on successful parse”, so that they only run if you explicitly refresh them from the Inspection Results toolwindow;
- Set inspection severity to “Do not Show” for inspections that could produce thousands upon thousands of results, like “use meaningful names” if you’re into Hungarian Notation for example, or “use of bang operator” if that’s the only way you’re ever accessing recordset fields in Access;
Other general performance tips:
- Rubberduck parses per-module, so when you leave a module after modifying it, trigger a parse – by the time you’re in the other module and have scrolled to where you want to be and are in that mindset, the modified module will have processed.
- Reduce coupling: the more modules are inter-dependent, the more modifying a module requires re-resolving identifier references in the dependent modules.
- Avoid complex grammar: bang operators, among other code constructs, are somewhat ambiguously defined and ultimately parse in two passes, with the first one failing. The standard member call syntax parses faster, in a single parser pass.
Undesirable Interactions
If you are using the free but rather old 32-bit MZ-Tools 3.x productivity add-in, this section shouldn’t be a concern. However MZ-Tools 8.x was rewritten from the ground up, ported from VB6 into .NET-land, and while its author Carlos Quintero took extraordinary steps to isolate MZ-Tools from other in-process .NET add-ins and has issued recommendations for Rubberduck to do the same, …there is still a chance the two add-ins bump into each other; if MZ wins, RD is essentially bricked.
MZ-Tools normally runs inside its own .NET AppDomain, except when hosted in AutoDesk products (Inventor, AutoCAD), which implement VBE initialization in a way that breaks MZ-Tools’ startup mechanics – up until recently it was assumed this collision only happens in AutoDesk hosts, but a recent support ticket involving Microsoft Access was filed and implicates interactions with MZ-Tools.
This issue manifests itself with InvalidCastException being thrown at various points, often during initialization, or later during parse: the exception message involves attempting to cast COM objects like Microsoft.Vbe.interop._VBProject into types such as VBClassicExtensibility.VBProjectClass, where VBClassicExtensibility is defined by MZ-Tools, not Rubberduck.
One thing that can be attempted to mitigate this problem, would be to set MZ-Tools to not load on start-up, and manually load it after Rubberduck has initialized… but sadly this cross-add-in confused COM marshaling is simply not supposed to happen given MZ-Tools’ AppDomain mechanics, and we don’t really have any solutions for this – same as we don’t really have any solution for cases where COM registrations are broken (e.g. when multiple Microsoft Office product versions are running side-by-side but were not installed in chronological order – that’s an officially unsupported scenario, per Microsoft).
As a result, using Rubberduck together with other .NET-based add-ins cannot be considered a completely fail-safe scenario, and we have to treat this as a “known issue” here, and the work-around sucks and boils down to “drop other add-ins, or drop Rubberduck”. This is actually probably true at various degrees of all .NET-based VBIDE add-ins.
On the bright side, we have taken several steps in this release cycle to prepare the ground not only to get Rubberduck to build correctly in the latest & greatest Visual Studio 2019, but also to get most of our build process ready for .NET Core – so when .NET Core 5 is released in a few weeks, we can try to get Rubberduck to run on the shiny new Core framework, which theoretically makes AppDomain completely moot, and so we have very little incentive to work on getting Rubberduck to load its own AppDomain the way MZ-Tools does: if we can make Rubberduck build and run on .NET Core 5, then this problem should simply disappear… in theory.
Enhancements & New Features
This release does not introduce any new top-level Rubberduck features, but makes a number of very useful user-facing additions nonetheless, on top of the many under-the-hood enhancements made this cycle.
Surfacing Annotations
One of the most useful and powerful features of Rubberduck, annotations are special comments that use a particular but relatively simple syntax – these are all grammatically valid:
'@AnnotationName("text")
'@AnnotationName "text"
'@AnnotationName("text", 123) : there can be comments here
'@AnnotationName "text", 123
'@AnnotationName Identifier1, Identifier2, ...IdentifierN
While the syntax itself is reasonably simple to use, the problem was that unless you knew every supported annotation, well then the @AnnotationName part kind of had to be a guess.
Rubberduck uses these annotations for various purposes, from identifying Rubberduck test modules to keeping hidden module/member attributes in sync with these comments (this includes the ability to document and literally map Excel hotkeys using VBA comments). You can read everything we’ve documented about them on the project’s website.
In Rubberduck 2.5.1.x builds, we finally get new commands in the code pane and Code Explorer context menus, that bring up a dialog that gives us all the options to easily and safely annotate everything that can be annotated, using the correct syntax and arguments every time:


@Ignore annotation to ignore a specific inspection, can now be done without needing to know the exact name we decided to call that inspection class in Rubberduck’s source code!Encapsulate Field Enhancements
This particular refactoring has seen a terrific enhancement that makes it very easy to cleanly and quickly turn a set of public fields into Property Get/Let members, with a Private Type TClassName and a module-scope Private this As TClassName instance variable – and all properties automatically reading/writing from it. You can see this feature in action in the previous article.

Unit Testing
The Test Explorer now makes it easier to ignore one or more specific selected tests, or all tests under a given category/group, by exposing the context menu commands that add or remove the @TestIgnore annotation as appropriate; having this command in the Test Explorer makes it possible to annotate a test method while a completely different and unrelated module is maximized in the code editor.
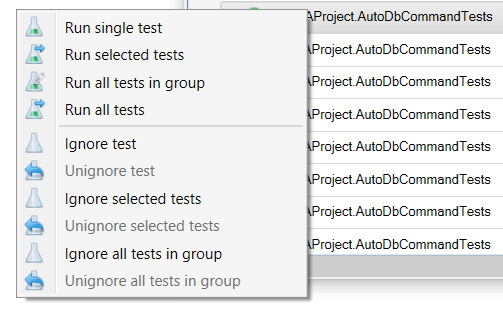
Running tests while results are regrouped by outcome is still a known issue (tests run painfully slow because the UI thread is busy re-sorting and re-rendering the list every time a test finishes running), but everything works much more smoothly when the tests are regrouped any other way.
Code Inspections
Ok the logic for that is currently broken on the website (working on that… somewhat) so this is much harder than it will be in the future when I’ll just look at the [New] tab on the inspections page of the website and every inspection that is in [next] but not in [main] will be listed right there. From skimming through every pull request merged since the last release:
- Function return value not used inspection now more clearly targets call sites, and now ignores non-user code.
- Function return value is always discarded inspection is the old “return value not used” logic targeting the function itself, when none of the call sites capture the function’s return value.
- Implicitly typed const inspection was added to flag
Constdeclarations without anAsclause to specify an explicit type. - Assignment not used inspection now correctly handles an assignment that is overridden in the next statement but first read in the RHS expression of the assignment.
Not user-facing but critically important nonetheless, is all the behind-the-scenes work done to simplify inspecting VBA code as much as possible. This cycle saw a tremendous amount of technical debt paid in the code inspections department, that pave the way for future enhancements like, say, having the ability to run inspections per-module; as the number of implemented inspections continues to grow, the ability to scope inspections in a more granular way is going to be very useful for our plan to eventually report inspection results in a custom code pane, with colored squiggly lines (that’s v3.x stuff, though).
Applying Quick-Fixes
The Code Inspections toolwindow has been updated with a context menu that makes it much simpler to apply a quick-fix to one or more inspection results; all available quick-fixes appear in the context menu, each with various options to apply to the selection. This menu is also shown by clicking the “Fix” drop-down menu from the toolwindow’s toolbar.

Code Explorer Enhancements
The Code Explorer toolwindow context menu now includes a move to folder command to easily organize your project components, and there’s a new setting to enable drag and drop in Code Explorer (disabled by default):

With that setting enabled, you can now move a code file to an existing folder, simply by dragging it from its location and dropping it onto a folder node! The setting was made to require being explicitly enabled, to avoid discovering that feature by accidentally dragging a code file somewhere (that did happen in beta/testing).
Website Integration
You may have noticed rubberduckbva.com is “under reconstruction”. Before that, the site’s content was mostly static, with only the inspections list assembled from content parsed from the Rubberduck.CodeAnalysis.xml, downloaded periodically off GitHub through unauthenticated REST API requests. That worked relatively well until a spike in traffic occurred following the release of Excel Insights, a book collectively authored by 24 Microsoft MVP Award recipients, including myself: suddenly a bug in the caching mechanism became very apparent when the site’s home page started getting served as a wonderful HTTP 500 error page.
Since the website hosting came with a SQL Server database that I wasn’t using, I decided to start using it and make the site pull the content from there rather than directly off the GitHub API. I wrote a small console application, got myself a private API key to make properly authenticated REST API requests, and now there’s a scheduled task running on a virtual machine in my garage, that runs this application every 30 minutes to update the installer asset download counts and verify whether the XML documentation assets are up-to-date for the latest pre-release build, and then proceeds to parse the XML docs and generate/update the database records: the website simply pulls the data from the database at every request, and now the website couldn’t bust GitHub’s REST API limits even if it tried.
Documenting Rubberduck is challenging: there are a lot of features, and there isn’t really any user guide that’s constantly being kept up-to-date. The wiki on the repository is terribly outdated in several parts, and the feature announcements on this blog are nice when you’re following the project along its journey, but in a dream world using Rubberduck would be content found on the website, and contributing to Rubberduck would be content found in the repository’s wiki.
Parsing the xml-docs into website content is a step in that direction. Nobody wants to maintain documentation, but xml-doc comments are part of the source code, and we even put source code analyzers in place that will break the build if we try to introduce an inspection, quick-fix, or annotation, without properly documenting it with xml-docs.
Every single inspection, quick-fix, and annotation has thorough documentation, including code examples that may span multiple modules. But best of all, every single page generated from source code includes an “edit this page” link that points to a GitHub page where you can literally edit the xml documentation for the inspection you were looking at (and review its source code if you like – it’s the same file!) – and just like that, all you need to contribute to Rubberduck (yes, single-character typo fixes and additional useful code examples are welcome!) is a GitHub login!
Because of how the request routing on the website was setup, it was easy to make Rubberduck link in-app inspection results to this website content – you can now click a URL at the bottom of the inspection results toolwindow (this will likely change one way or another in the future) to bring up the details page with the xml documentation and code examples:

The in-app content exists as localized resources, lovingly translated by our international contributors; the website content however, is only available in English, because we’re absolutely not going to start translating XML comments in the source code. But the processed content actually resides in a database, so it wouldn’t be impossible to eventually localize it at that level, as well – we’re just not there yet at all at the moment.

The revamped rubberduckvba.com domain will ultimately span 3 sites, including api.rubberduckvba.com, which will eventually expose REST endpoints for various purposes, including Rubberduck’s “check for newer version at startup” feature; for example something like api.rubberduckvba.com/indenter.json that might accept some VBA code in a JSON object in the request’s body, and respond with a JSON object in the response body containing the indented VBA code. Or api.rubberduckvba.com/inspect.json that might also accept some VBA code (presumably along with some metadata about the module type) in a JSON object in the request’s body, but could respond with a JSON object representing all inspection results for it. It’s still all just brewing ideas at this stage. The other subdomain, admin.rubberduckvba.com, is going to host a web-based, GitHub-authenticated version of the VBA program I’m going to present in my next article: a tool for managing and editing most of the website’s content.
Moving Forward
Rubberduck is becoming a pretty mature code base and has an ever-increasingly better abstracted internal framework/API to understand and manipulate VBA code. The project now builds with the latest version of Microsoft Visual Studio 2019, and we’re hoping COM Automation support in .NET Core 5 will allow us to build an increasing number of the project’s components with it; I’m thinking the “main” type library is better off under the old tech, but I’ll be more than happy to be proven wrong here!
A rough roadmap for v2.5.1.x might include…
- More resolver capabilities unlocked by fully leveraging our internal ITypeLib API
- Syntax-highlighted preview of the changes for all refactorings (and quick-fixes?)
- Some Code Path Analysis API, to help implement the more complex inspection ideas
- The Moq wrapper mocking framework
- Block Completion, maybe
- Anything else anyone feels like contributing to the project!
The goal for the rest of the 2.x cycle is to prepare everything that needs to happen in order to implement our own custom code editor window – giving us full, complete control over every single token and everything that can possibly happen in that custom code pane. We’re talking code folding, custom theming, that kind of thing.
‘Main’ vs ‘Master’ – Why it Matters
You may have noticed (or not) that the website is now labeling “main” the branch formerly known as “master”. As a French native, “master/slave” terminology in any non-actual master/slave context has always sounded a bit weird to me, but I’m a white man in North America (although not in the US) and I get the luxury to read these words and decide that they don’t affect me, and reflecting on the events of this summer has taught me that this is part of what white privilege is.
I don’t do political & editorial commenting, I prefer to leave that space to others – but I warmly recommend watching 13th on Netflix and, if you can handle it, When They See Us. Black lives matter, it’s simple – and no, it doesn’t say “but white lives don’t” anywhere between the lines.
So yes, we’re going to be taking steps to alter the language in Rubberduck a bit in this cycle. The “master” branch will be renamed to “main”, yes, but we’ll also come up with a better term for “white-listing” identifier names. It won’t stop racism, no, indeed. But it won’t hurt anyone, either.
Peace!

Thank you all. Great job
LikeLiked by 1 person
Keep up the good work!
LikeLiked by 1 person
The terms I’ve heard so far for “white-listing” and “black-listing” are “accept-list” and “deny-list”
LikeLiked by 1 person